HTML SANITIZER vs. XSS (Case study)

Mở đầu
Our story on XSS begins in late 1999 with a small group of Microsoft security engineers. The Microsoft Security Response Center and the Microsoft Internet Explorer Security Team had been hearing of attacks some sites were experiencing wherein script and image tags were being maliciously injected into html pagesRef: https://medium.com/@ryoberfelder/describing-xss-the-story-hidden-in-time-80c3600ffe81
Đã 22 năm kể từ lần đầu tiên có người thấy sự xuất hiện và ghi nhận lại lỗi bảo mật Cross-Site Scripting (XSS) như bài blog ở trên đã đề cập. Nhưng cho đến khi mình đi hội thảo OWASP AppSec 2019, đa số các bài nói vẫn bàn về XSS và làm sao có thể phòng chống nó: áp dụng Content-Security-Policy (CSP) như thế nào để chống XSS, chi phí khi áp dụng CSP, …
Đủ để chúng ta thấy rằng, để sửa một loại lỗi bảo mật rất đơn giản nhưng lại không hề đơn giản.
Có rất nhiều cách phổ biến để chống loại lỗi XSS này:
- Escaping
- Sanitizer
- Filter
- WAF
- Content-Security-Policy
- …
Riêng bài hôm nay mình muốn chia sẻ một case khá hay khi việc tự tạo một Sanitizer bỏ sót những trường hợp ngách của HTML dẫn đến việc bị có thể bị bypass.
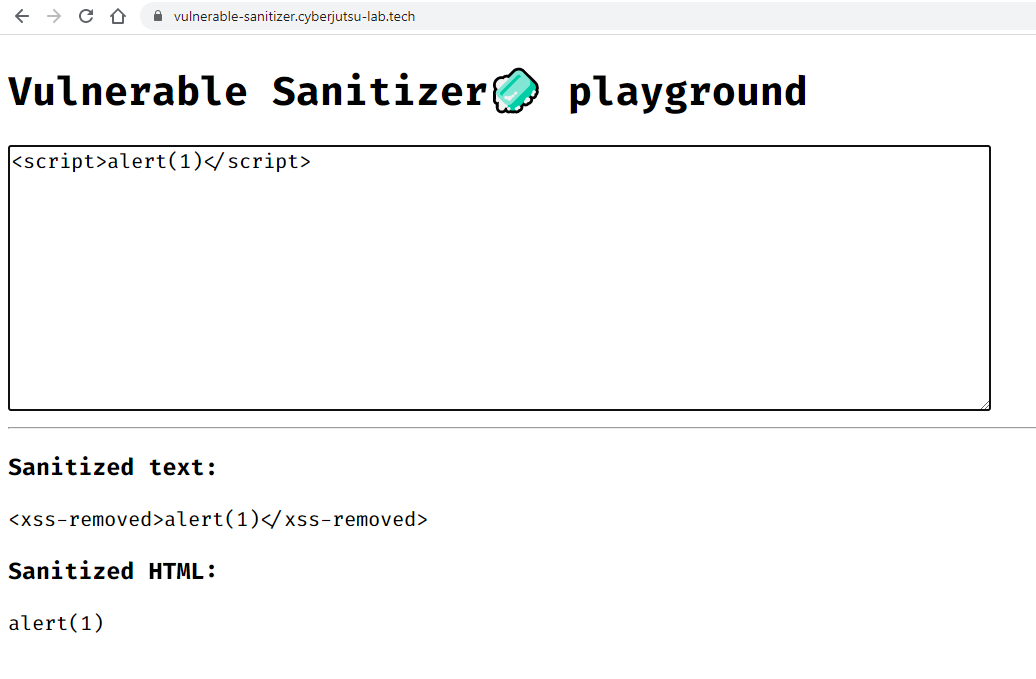
Để dễ liên tưởng hơn, mình cũng đã setup một playground mô phỏng lại lỗi này (không hoàn toàn chính xác 100% như case study vì mình không biết chính xác các thuật toán đằng sau) tại: https://vulnerable-sanitizer.cyberjutsu-lab.tech/
Các bạn có thể vừa đọc và thực hành trên đấy nhé!
P/S: Nếu bạn còn mới lạ với XSS thì nên xem video XSS Hacking để nắm một số khái niệm nhé.
Storyline
Lỗi bảo mật này được tìm ra trong khi tụi mình đang trong một dự án nhỏ là thử nghiệm một số tool mà CyberJutsu.Team7 tạo ra để hỗ trợ việc tìm lỗi Client-side cũng như công cụ log tập trung để giúp quá trình teamwork khi săn lỗi bảo mật.
Nhớ hôm đó là vào buổi khuya tháng 08/2020, mình truy cập trang https://███████/ (Vì yêu cầu của bên chương trình bounty, bên mình không được phép disclose tên ra) và thực hiện các bước kiểm tra cơ bản.
Sau một khoảng thời gian ngắn, có một chức năng ngay lập tức mình chú ý đó là khung Tìm kiếm.
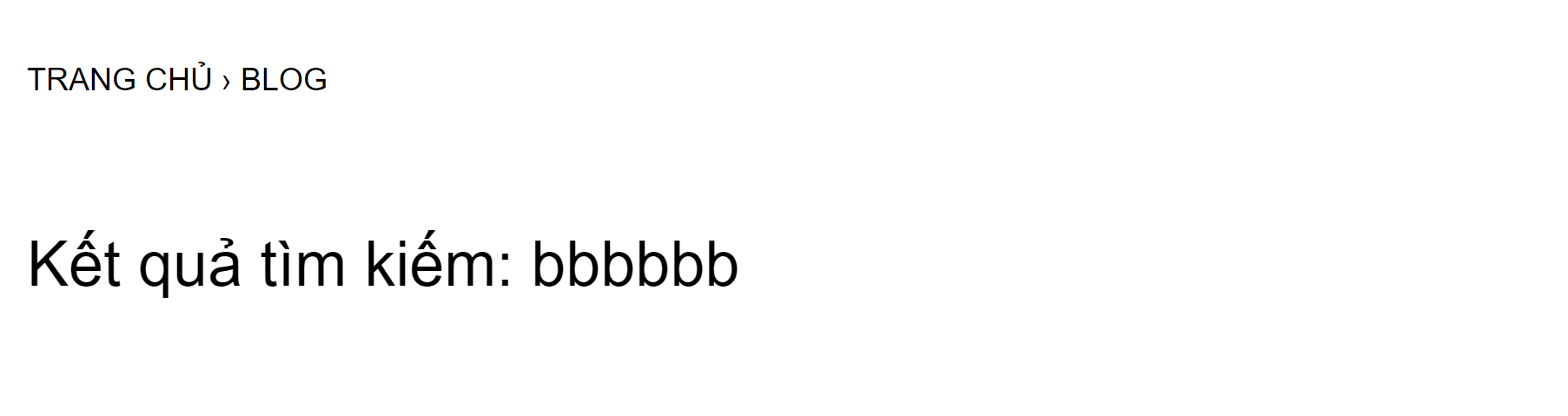
Vẫn như thói quen mình đặt vào ô tìm kiếm một chuỗi HTML đơn giản để kiểm chứng: bbbbb<h1>abc</h1>

Gotcha, một khởi đầu suôn sẻ khi nhận thấy rằng bộ lọc (sanitizer/filter) của trang này không lấy mất đi tag HTML <h1> của mình, có vẻ đây là một chỗ có khả năng khai thác lỗi Reflected-XSS.
Mình bèn thử thêm một vài tag HTML ví như: bbbbbb<img src="cyberjutsu">
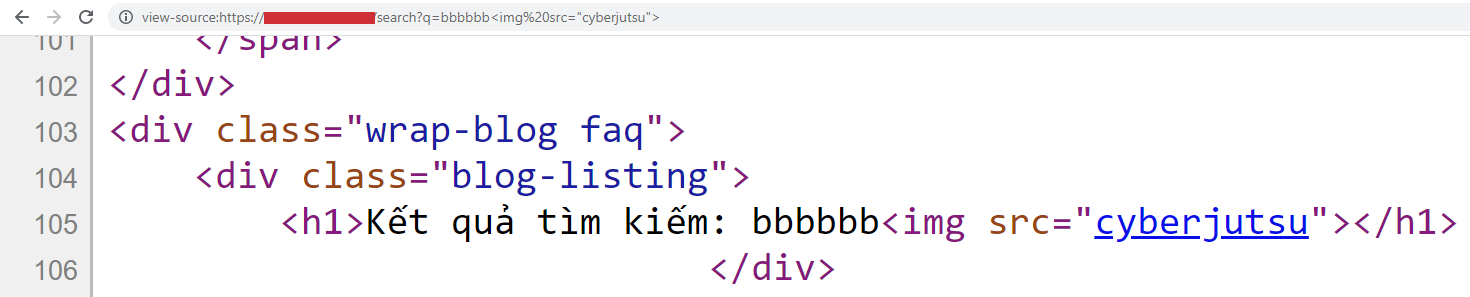
Vẫn ổn, mình đã nghĩ trong đầu: “Ồ thế thì chắc bị XSS rồi, không lẫn vào đâu được”
Tiếp đến, mình khai thác sâu hơn bằng cách đưa một event handler của tag <img> vào có thể trigger JavaScript lên: <img src="cyberjutsu" onerror="alert(1)"> (nôm na là: khi tấm ảnh này load không thành công, sự kiện onerror sẽ được kích hoạt và chạy lệnh JavaScript mà ta đã gán cho nó, đây là một attack vector khá nổi tiếng của XSS)
Nhưng kết quả lại không như mong muốn, dễ thấy rằng, attribute onerror trong payload của mình đã bị removed. Tới lúc này, mình nhận ra trang web này thật sự có một bộ lọc gì đó đằng sau:

Không bỏ cuộc ở đó, vì rõ ràng chúng ta đã có thể chèn tag HTML vào được rồi, vì vậy cánh cửa tuy hẹp nhưng mình tin vẫn có thể lách được.
Mình thử một vài trường hợp khác để tìm hiểu sâu thêm nguyên lý của bộ lọc này:
1 | Thử những attribute không nguy hiểm: |
Mọi thứ nguy hiểm đều đã bị lọc đi và không khai thác được gì, nhưng, mình dần bắt đầu hiểu được cách thức hoạt động của bộ lọc đằng sau trang web này.
Điểm đặc biệt là bộ lọc này không cố gắng lấy đi hết tất cả các tag HTML như chúng ta thường thấy mà nó chỉ loại đi những attributes có thể trigger được JavaScript (onerror|onclick|onfocus|...) hoặc những tag HTML nguy hiểm (như <script> | <svg> | <iframe>)
Cơm thêm
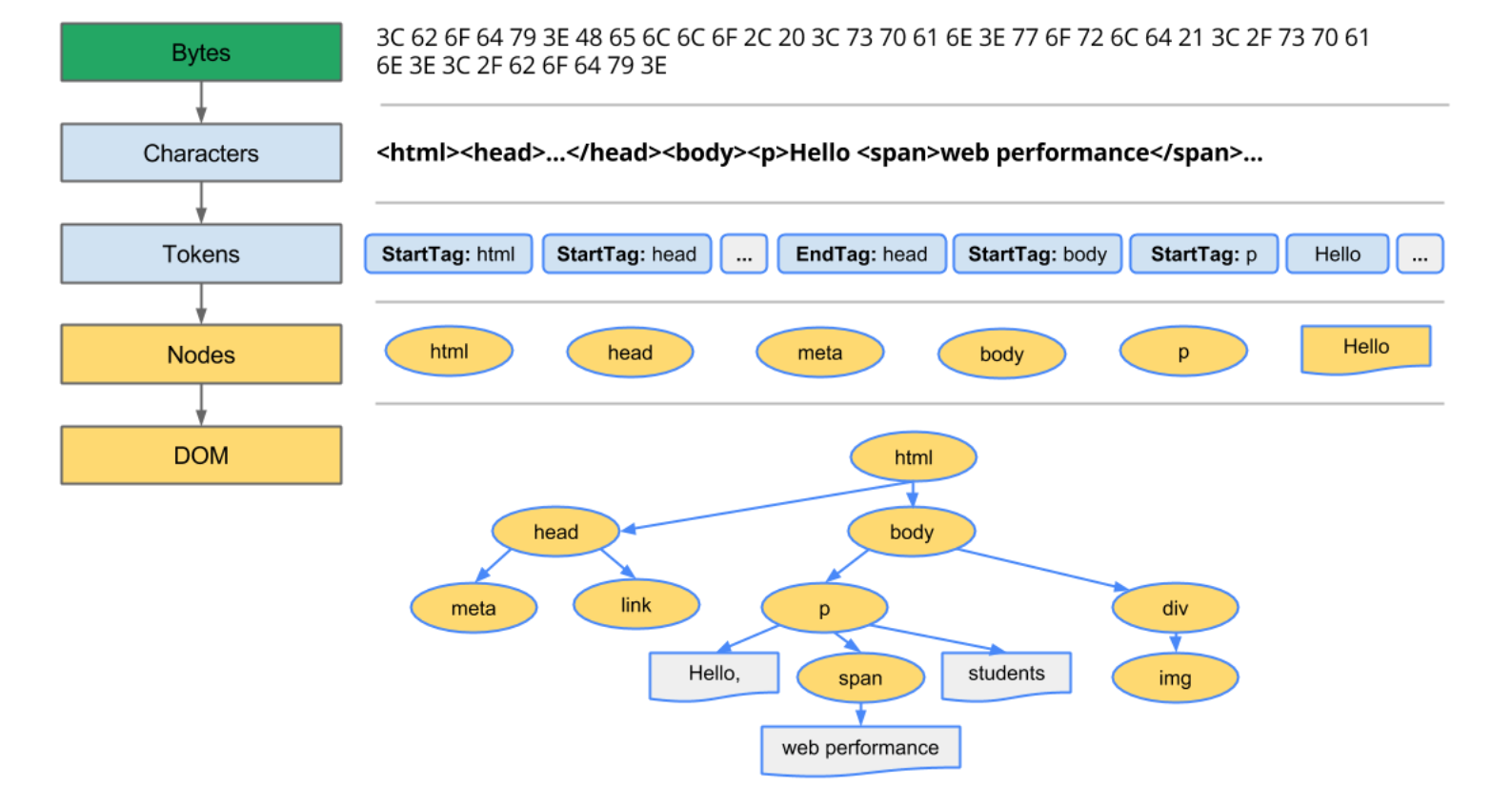
Minh họa thêm về quá trình parse và tạo ra cây DOM, thì đây là một diễn biến khi trình duyệt gặp những tag HTML, sẽ xử lý nó để tạo ra các nodes trong cây Document Object Model. Sau đó trình duyệt mới tiến tới bước tiếp theo là render ra những hình ảnh dựa trên cây DOM này [1]
Đi sâu vào HTML spec
Có vẻ không làm được gì khác, thì bỗng mình có một ý tưởng khác.
Vì trong dạo thời gian tháng 08/2020, có rât nhiều bài blog nói về một số kĩ thuật XSS mới làm mình nhớ về một số tag HTML đặc biệt đó là:<style>
Vì sao nó đặc biệt? Nhìn vào HTML spec của tag <style> này ta thấy rằng Content Model của tag này là Text
Nó mang ý nghĩa là gì, mình có một ví dụ để ta có thể dễ thấy.
Mở trình duyệt và thử tạo một chuỗi HTML bằng cách truy cập đường dẫn như sau:
data:text/html,<style><h1>Hello world</h1></style>
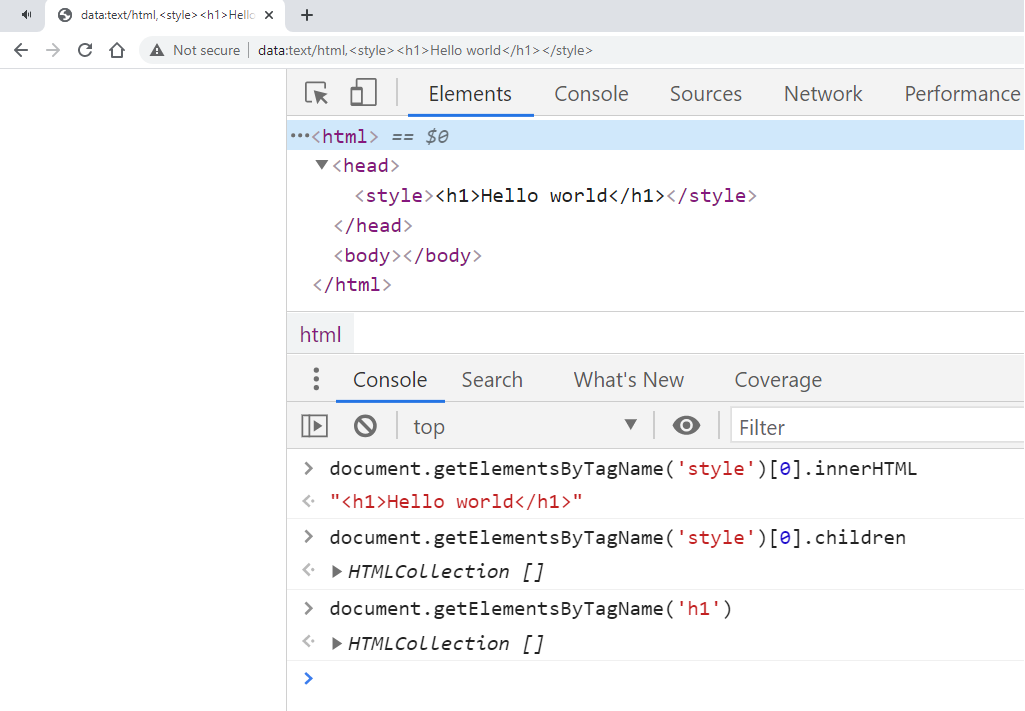
Ta có thể thấy element <h1> không hề hiện diện trên DOM-tree. Nhìn kĩ ta cũng sẽ thấy là đoạn chuỗi <h1>Hello world</h1> cũng không hề được highlight trong DevTools, chứng tỏ nó chỉ được coi là một chuỗi text đơn thuần và được highlight là màu đen.
Ý nghĩa rằng tất cả mọi thứ nằm trong tag <style>... sẽ được đối xử như là Text đơn thuần và HTML parser sẽ ngưng parse khi và chỉ khi gặp một tag đóng của chính nó là </style>
Đặt ra một tình huống phức tạp hơn khi kết hợp nhiều thứ lại: Khi ta cố gắng thử lồng tag đóng </style> vào trong một attribute của tag <p> như sau:
data:text/html,<style><p title="</style><h1>Hello world</h1>">
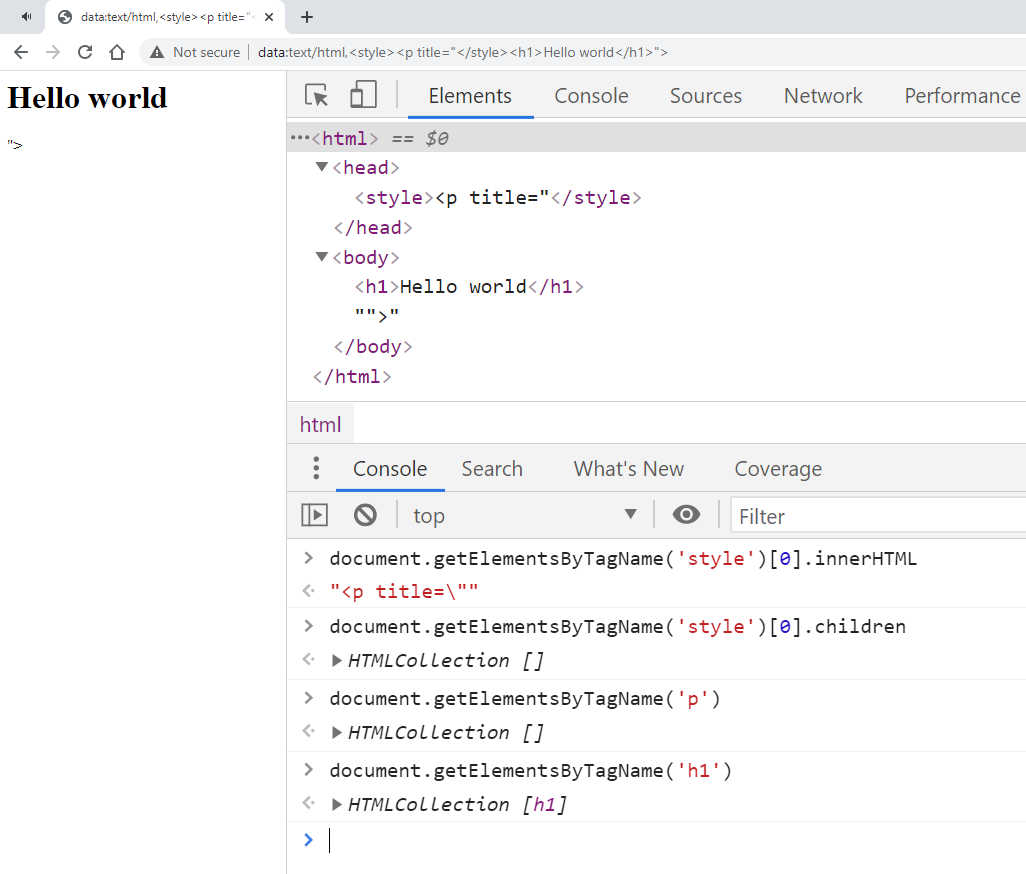
Nó hoạt động đúng như nguyên lý mình vừa đề cập: <p title="..."> không hề được coi là một tag HTML mà chỉ là một chuỗi text đơn thuần, dẫn đến việc, ngay sau khi tag </style> được đóng lại. Trình duyệt lập tức duyệt tới tag tiếp theo là <h1> và xem nó là một element HTML hợp lệ. Và như các bạn thấy chuỗi “Hello world” đã được tô đậm với tag <h1>
Còn nếu ta bỏ tag <style> ở đầu đi, thì rõ ràng trình duyệt sẽ xem tất cả dữ liệu trong nháy kép "..." là nội dung attribute title và không hề render tag <h1>Hello world</h1> (được DevTools highlight như là màu xanh)
data:text/html,<p title="</style><h1>Hello world</h1>">
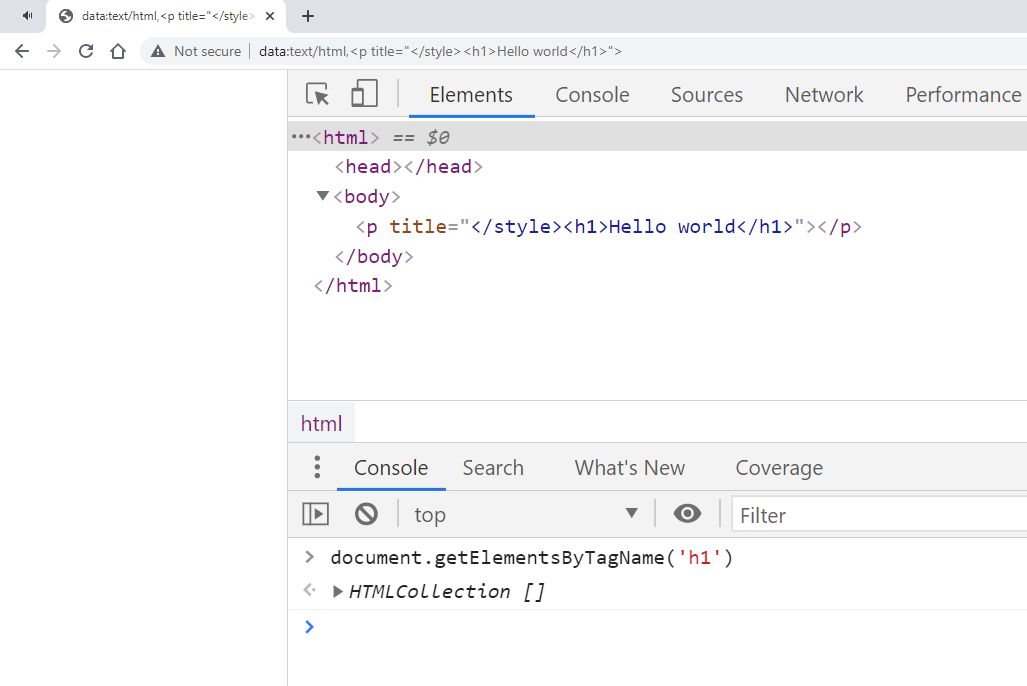
Điều này càng chứng minh rõ là HTML parser của trình duyệt sẽ vẫn cứ tuân theo nguyên tắc ta đã bàn ở trên, xem tất cả nội dung ở trong tag <style> là text, không parse chúng thành HTML nodes và quá trình này chỉ ngưng khi gặp tag đóng </style>
Ngoài <style> có đặc điểm như vậy, ta cũng có thêm tag <script> có nguyên lý tương tự.
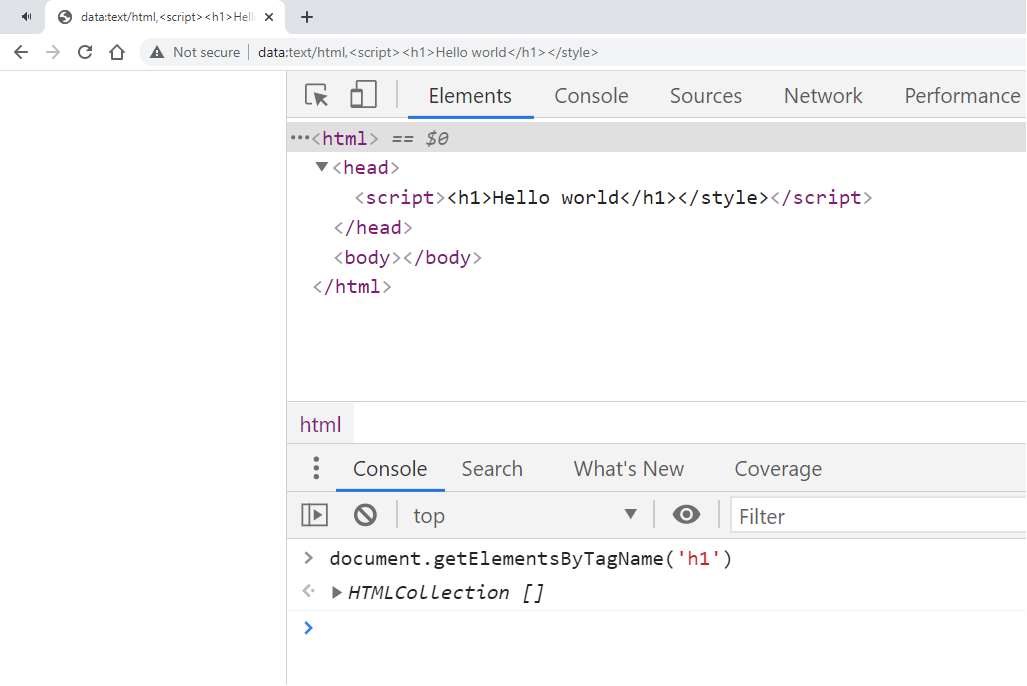
Đợi đã, như vậy thì nó giúp gì cho trường hợp này?

Kết hợp mọi thứ lại
Như ta đã khám phá ra, nguyên lý hoạt động của bộ lọc này là cố gắng chạy qua và scan hết tất cả các tag HTML và attribute của nó, tìm ra những thành tố nguy hiểm có thể bị khai thác và loại bỏ đi.
Lỗi bảo mật xuất hiện khi mà những trường hợp ngách xuất hiện.
Sẽ ra sao nếu mình đặt vào khung tìm kiếm của website ███████ một câu như sau:
<style><p title='</style><img src="a" onerror="alert(1)">'>
Như ta đã test ở đầu bài, chuỗi <p title="..."> được xem là một tag HTML với attribute title ✅ hợp lệ, không nguy hiểm gì, cho nên bộ lọc đã cho phép đi qua.
Vì dù tag <img onerror> có xuất hiện ở trong chuỗi nhưng vì bản chất của bộ lọc là đi qua hết tất cả các tag HTML và attribute để tìm ra những thành tố nguy hiểm.
Tuy nhiên… cách hoạt động của bộ lọc không hề giống với những gì trình duyệt thật sự làm vì do cách trình duyệt xử lý tag <style> như mình đã nói phần trên là rất đặc biệt. Bộ lọc không hề biết điều này… vì thế mà chuỗi payload: <style><p title='</style><img src="a" onerror="alert(1)">'> đã được cho qua ✅
Đến đây mình khá chắc về ý tưởng của mình sẽ thành công, tuy nhiên tag <style> cũng bị bộ lọc trên website ███████ xem là nguy hiểm nên đã lọc đi…
Không dừng lại ở đó, mình đi tìm thêm những tag HTML mà có tính chất tương tự (vì rõ ràng tag <script> cũng đã bị cấm). Một lúc sau và mình đã phát hiện ra một tag khác mà có Content Model là Text node đó chính là: <noscript>
Liền thử và BAM: <noscript><p title='</noscript><img src="a" onerror="alert(origin)">'>
Mình đã thành công chèn vào nội dung page với tag <img src="a" onerror="alert(origin)"> và thực thi được mã JavaScript trên trình duyệt của nạn nhân nếu họ click vào đường link:
1 | https://███████/search?q=bbbbbb%3Cnoscript%3E%3Cp%20title%3D'%3C%2Fnoscript%3E%3Cimg%20src%3D%22a%22%20onerror%3D%22alert(origin)%22%3E'%3E |
Kết luận
Chúng ta có thể thấy việc tạo ra một bộ lọc để chống lại một lỗi bảo mật là đầy thách thức vì kiến thức của mỗi người là có hạn (mình cũng đã không thể bypass case này nếu không đọc những nghiên cứu của người khác). Giải pháp ở đây có thể là chúng ta nên tham khảo những cách làm/thư viện đã có sẵn của các tổ chức bảo mật uy tín.
Ví dụ như: DOMPurify, hoặc thậm chí sắp tới các trình duyệt đều sẽ có Sanitizer API cho mình. Cùng chờ xem, liệu giải pháp mới có xin ra những vấn đề mới nào khác không nhé ;)